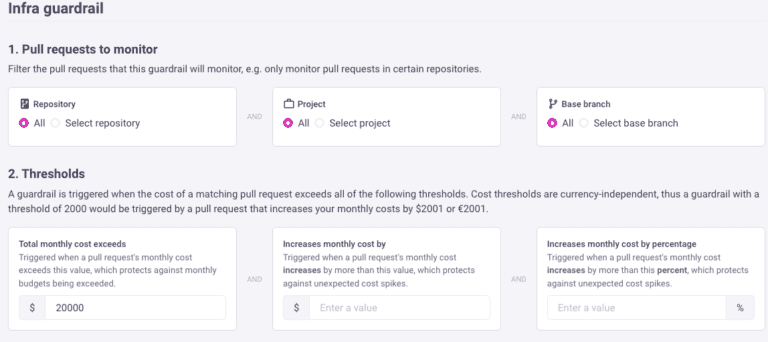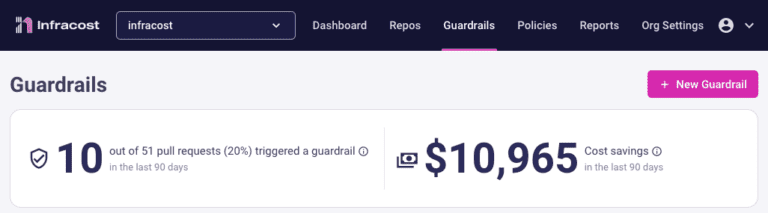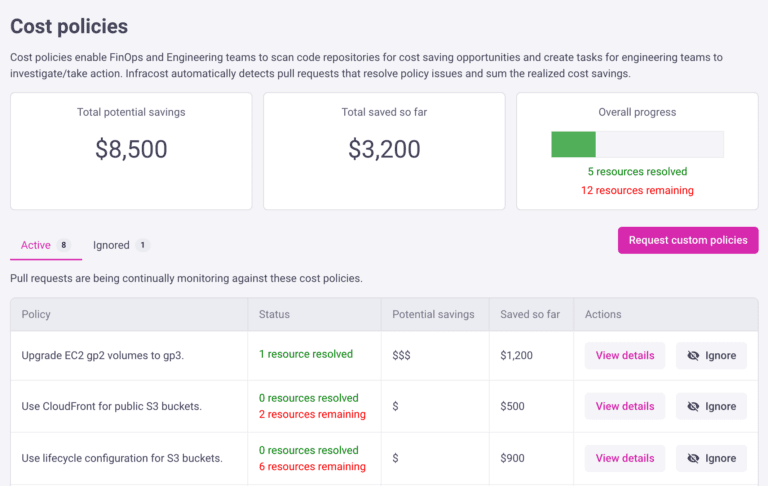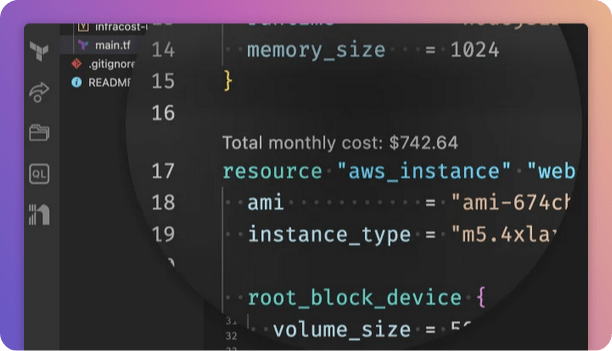
June 2023: New GitLab And Jira Apps, VS Code Extension & Data Export!
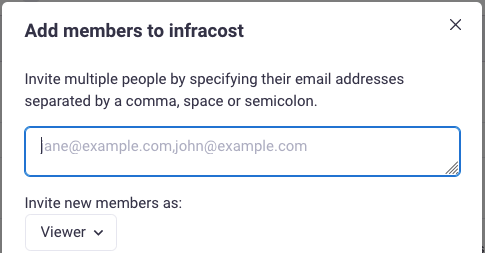
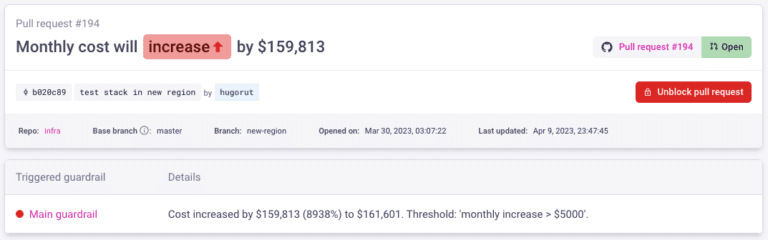
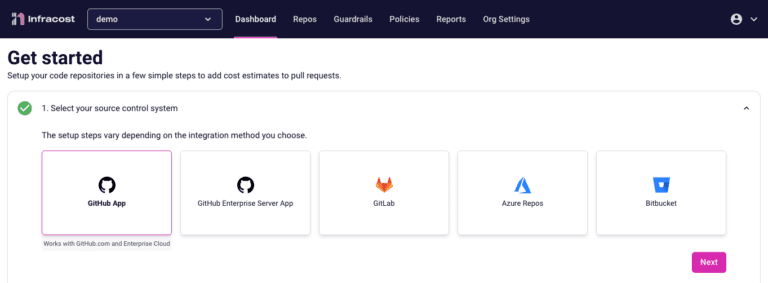
We recently released a new GitLab App that enables you to quickly add Infracost to all of your repos with a few clicks. We also released a new Jira app so product managers and budget owners know the cost impact of a feature request or change, before deployment! There’s also a new version of the…