
We redesigned the Infracost CLI for agent callers and cut Claude's output token usage by up to 79% and API cost by up to 67% versus a bare-Claude baseline. Benchmark: 16 questions over a 3-project Terraform fixture with 1,171 resources, Opus, 5 repeats per question.
Quick context: Infracost has a CLI that reads Terraform, CloudFormation, and CDK and tells you what a change will cost before you deploy it (see screenshots on https://cost.dev). It runs in CI on pull requests so reviewers see "this PR adds $400/mo" alongside specific suggestions: previous-generation instance types, DBs on old versions racking up extended support fees, mistagged resources, things like that. Increasingly the caller isn't a human or CI runner; it's Claude Code or Cursor invoking us as a subprocess.
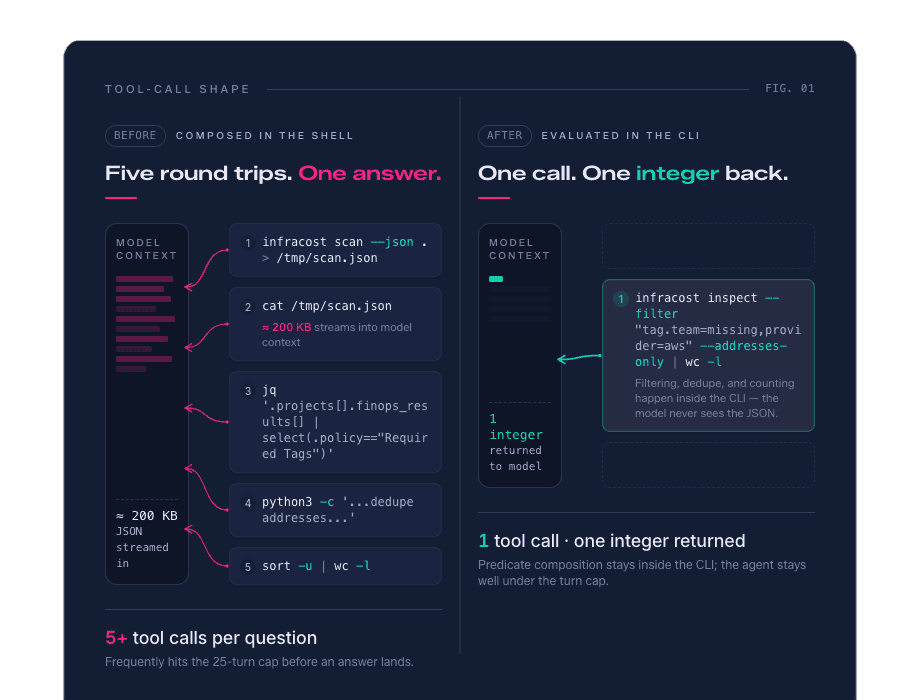
One question from the benchmark makes the problem concrete: "count distinct resources failing the tagging policy, deduplicated across projects." Bare Claude burned $3.51 writing Python parsers against our JSON, hit the 25-turn cap in our test harness, and as a result returned no answer. After the redesign: right answer, $0.25.
If you maintain a CLI that AI coding agents call as a subprocess, the same redesign moves likely apply to your tool: predicate pushdown into the CLI rather than jq pipelines composed in shell, and a token-efficient output format on the agent path. Neither is individually novel. The benchmark harness was what surfaced each gap and let us measure the cost of leaving it open.
In redesigning a new version of our CLI we approached the LLM case first because it was the largest gap in our understanding, not because it was the primary user. Human usage we can observe: docs analytics, support tickets, GitHub issues, our own daily use. Agent usage is opaque to us; the subprocess invocations happen inside someone else's harness and we never see them. Too many unknown unknowns to leave not investigated. The changes also improve the human-facing CLI in concrete ways; we'll come back to that toward the end.
The harness
The benchmark runs each of 16 questions across three configurations against a 3-project Terraform fixture with 1,171 resources.
The three configurations are:
bare-tf. Claude with Bash and Read tools,
-disable-slash-commands, no skill loaded. The agent has access to the.tfsource and a shell.skill-llm. The infracost-scan SKILL.md is loaded via
.claude/skills/, with an appended instruction to pass-llmfor machine-readable output.skill-json. The same skill loaded the same way, with the appended instruction recommending
-jsoninstead.
Comparing bare-tf against skill-llm isolates the value of the skill plus the LLM-targeted output path. Comparing skill-llm against skill-json isolates the value of the output format itself, holding the skill constant.
Several aspects of the harness needed attention before the measurements were trustworthy.
Sandboxed HOME for bare-tf cells. If the operator running the benchmark has the skill installed in their global Claude Code config, bare-tf is not bare. Each bare-tf cell runs with HOME pointed at a fresh, empty directory. That breaks the OAuth credential lookup, so the harness requires CLAUDE_CODE_OAUTH_TOKEN as an environment variable and errors at startup if it is missing.
Project-local TMPDIR. macOS sets ACLs on /private/var/folders that prevent subprocesses with different effective uids from traversing parent-created temp paths. Claude Code's sandboxed shell hits this. The harness sets TMPDIR to a project-local cache directory before any subprocess fires.
PATH-prepended infracost binary. The harness builds infracost from the current branch and prepends its directory to PATH for cell subprocesses. Trusting whatever infracost the operator has on their PATH would have silently disabled --llm against older binaries.
Repeats with averaging. Default is 5 repeats per cell. Cell-level non-determinism on cost and token counts is in the 20-30% range. Averaging is required for the comparisons to mean anything.
Re-run and re-score. A cell that hit the turn cap does not have a useful cost number. The --rerun-failed flag re-runs only those cells. When the verifier itself changes (we adjusted the integer extractor at one point because the model kept returning answers wrapped in backticks), --rescore re-applies the verifier to existing transcripts without spending the API budget again.
What the data showed
Run on the Opus model, 5 repeats per cell, all 16 questions:
Metric | bare Claude | skill (LLM format) | Δ |
|---|---|---|---|
Correct (Q&A) | 5 / 11 (45%) | 11 / 11 (100%) | +6 |
Total cost (USD) | $16.41 | $9.63 | -41% |
Output tokens | 207,017 | 81,697 | -61% |
Wall time | 50 min | 50 min | tied |
The aggregate numbers obscure a bimodal distribution. The 11 scoreable questions split into two buckets.
Easy questions (5 of 11). Total monthly cost, most expensive resource, which mandatory tag key is missing on the most resources. Bare Claude has reasonable priors from raw .tf source. It can guess that an EKS cluster costs more than an S3 bucket. It can regex over tags = {…} blocks. It got 5/5 of these for $4.20. The skill got 5/5 for $1.52.
Hard questions (6 of 11). Distinct-resource counts deduplicated across projects, total potential monthly savings if every FinOps issue were resolved, full lists of resources failing tagging policy. Bare Claude got 0/6 while spending $7.61 trying. The skill got 6/6 for $2.48.
One run is worth pulling out. Question d1 asks for the count of distinct resources failing at least one tagging policy, deduplicated across all projects. Bare Claude attempted to solve this by writing Python scripts to parse .tf files. When their output did not match the question, it wrote more Python. It hit the 25-turn cap with no answer after $3.51 of API cost. The skill produced the right answer for $0.25 by running:
The version above is what the model produced at benchmark time. The skill has since been updated to teach infracost inspect --summary --fields distinct_failing_tagging_resources for this question, which uses a pre-computed de-duplicated count and skips the wc -l pipe.
The remaining 5 questions (the fix-tasks) ask for unified Terraform diffs. Validating that an arbitrary Terraform diff is correct is its own research problem; there is a wide space of acceptable answers. Those questions are scored on token cost only.
Diagnosis: where the tokens go
The headline numbers above describe the current state. In earlier runs, before the predicate flags described in the next section landed, traces on hard questions included pipelines like:
Each subprocess in that pipeline streams its output back through the model's context. The output of cat /tmp/scan.json for a moderate Terraform tree runs to 200KB or more. Every line is read by the model, accounted for in the input token bill, and reasoned about before the next step is planned. The cumulative cost of a five-stage pipeline against a JSON dump is large, even before the model writes the second-pass Python script that the question often required.
The model was composing the slicing logic itself, in token-expensive subprocesses, because the CLI did not expose the predicates it needed.
CLI changes: predicate pushdown
The fix was to push the predicates into infracost inspect. The new flags cover the slicing patterns that appeared most often in the traces:
-addresses-onlyis an alias for-fields=address.-filteraccepts a comma-separated, AND'd grammar ofkey=valuepredicates. The grammar is small enough to teach the model in a paragraph and expressive enough that any common slice is one flag combination away.
Behavior after these flags landed: the model stopped writing pipelines. Where it had been chaining jq, python, sort, and wc, it produced a single infracost inspect invocation that returned the answer directly. Output tokens on the hard bucket dropped from 113K to 24K, a 79% reduction.
The principle is standard CLI design. The closer the predicate runs to the data, the cheaper the query. What changed was the meaning of "cheap." It now refers to per-token API costs against a 200K-context model, with the bill arriving on a credit card.
Output format: TOON
JSON's overhead for an LLM consumer is field name repetition. A 500-row table with 5 columns pays for "address": 500 times. For a human reading a --json dump, that redundancy is useful. For a model that is about to count, sum, or filter, it is tax.
The --llm flag routes output through TOON (Token-Oriented Object Notation), an indentation-based format with a third-party spec at toon-format/spec. The relevant property is shape detection on arrays. When an array contains uniform objects (every element has the same keys, all values are primitives), TOON emits a single header line followed by comma-separated value rows.
The encoder logic is short enough to quote in full. From internal/format/toon/toon.go:
uniformObjects walks the array and confirms every element has the same key set with primitive values. If it does, the array renders as a single header line followed by comma-separated value rows. A five-issue slice of a FinOps report shows the comparison directly:
JSON-pretty (268 tokens, 942 chars):
TOON (125 tokens, 417 chars; -53% vs JSON-pretty, -25% vs compact JSON):
Token counts are measured with the GPT-5 o200k_base tokenizer that TOON's published benchmarks use. The same tabular shape applies to the multi-hundred-issue payloads typical of real Infracost scans, where the header amortizes across more rows and the percentage savings grow.
Heterogeneous arrays fall back to an expanded form closer to YAML. TOON's data model is JSON-equivalent. Types implementing json.Marshaler (we have a rat.Rat rational-number type for currency values) are encoded through their JSON form, so wire semantics stay aligned with --json.
TOON's published benchmarks measure roughly 35% fewer tokens than minified JSON on uniform tabular datasets, and 59% fewer than pretty-printed JSON (benchmarks, GPT-5 tokenizer). Comprehension accuracy on the same benchmark is roughly equivalent to JSON (76.4% versus 75.0% across four models), so the format change does not trade off correctness for compactness. On Infracost's --json output, which is compact and dominated by uniform arrays of FinOps issues, the savings sit in the 30-40% range.
The decision was whether to adopt TOON, write our own format, or stay on JSON. Writing a one-off would have required teaching every agent author about it. Staying on JSON would have cost roughly half the format-side savings. Adopting TOON costs us a 794-line encoder we maintain. That trade was straightforward.
Open items
A few gaps the harness surfaced that remain open.
Verification on fix-task questions remains coarse. Five questions ask for unified Terraform diffs and are scored on token cost only. A working verifier would apply the diff and re-run infracost scan to confirm policy compliance. That catches correctness but does not assess idiomaticity. We have a sketch and no shipped implementation yet.
Per-cell correlation is manual. The aggregate report joins cost and accuracy per format, but the per-question table shows only accuracy, and cost-by-verdict breakdowns (cheaper-but-wrong, expensive-but-right) still require querying the cell-level JSONL the harness writes alongside the report.
Carryover for human callers
The LLM case was the entry point because it was the largest unknown. The redesign carried into the human-facing CLI in several ways.
A human asking "which resources are over $100/month and missing the team tag" can now write:
The equivalent without the new flags is infracost scan --json | jq '.projects[].finops_results[] | select(...)' | .... The new flags do not replace jq. They cover the slice patterns that come up often enough to justify named flags. Anything outside that set continues to flow through jq against the JSON output, which is unchanged.
Existing scripts, dashboards, and CI pipelines that consume --json keep working without modification. The new flags are additive.
-addresses-onlyand-fieldsgive the caller a projection rather than the full record.-addresses-onlyreturns one resource address per line, which is enough for "how many" (wc -l), "share this list" (redirect to a file, or pipe intogh pr comment --body-file -), or any text-pipeline follow-on.-fields address,monthly_costproduces a narrow tabular view that fits in a terminal without horizontal scroll. Neither requires the operator to round-trip through-jsonandjqto recover a useful shape.
The result is a CLI that gives operators a shorter path to the answer they want, with the option of shaping anything beyond that through the existing JSON surface. None of these flags exist because we asked humans what they wanted. They exist because the benchmark made the cost of not having them legible, and the same shapes turn out to be useful at a terminal.
Why 2.0
We launched Infracost on HN five years ago, when the CLI did cost estimates and not much else. Earlier this year we were scoping a 1.0 release: the CLI would stop being just a cost-estimation tool and start surfacing the issues behind the costs: previous-generation instances, policy violations, the kinds of issues a thorough PR review would catch. Then agent traffic started showing up, and it became clear the 1.0 scope was the right idea aimed at the wrong caller. A human reviewer reads a PR comment; an agent runs infracost inspect --filter ... and gets the same insight as a tabular row it can pipe into the next step. The flags above and the TOON format are how that information reaches a non-human caller efficiently. This resulted in a significant enough change from the path we’d been on with our 0.10.x releases that we’re shipping it as 2.0 and skipping 1.0. The capabilities are the same; the design center moved.
What generalizes
The harness gave us a fast feedback loop on CLI design choices that would have taken weeks of dogfooding to surface. We cannot run 16 questions across 5 repeats against human users and measure their effort the way we measure token cost. The harness itself does not generalize; the improvements it produced do.
Most of the changes that made the CLI cheaper for an agent are also changes that make the CLI better for a human at a terminal or authoring a CI script:
Targeted predicates instead of generic dumps.
Projection at the source.
A wire format that does not pay for redundant scaffolding.
The economic regime is what changed. Output is metered, the consumer is non-deterministic, and the consumer reads a large amount of context. The design moves are standard. They pay off more now because the consumer is, in dollar terms, less patient than a human.
The headline 41% number is a floor, weighted across questions where the skill barely matters. On the bucket where the skill does matter, cost reduction is 67% and accuracy goes from zero to one hundred percent. We did not have those numbers before the harness, and we did not know where to point a redesign without them.
The encoder, the new flags, and the harness are in the infracost/cli repository, see https://infracost.io/docs/ if you want to try it.



Infracost ROI Report
Learn how the ROI of shifting FinOps left is measured